








-
Personalize. Tailor content to users. Boost engagement. Drive revenue
-
Agile Creation. Faster content iteration. Stay ahead of your competitors
-
Seamless Collaboration. Centralized teamwork. Consistency

We migrated to a headless infrastructure to enable rapid A/B test iteration, which has driven a double-digit impact on our profit margin. We also love having the rigor of Git version control over our HTML, while giving our marketing team autonomy over the copy and content itself.
Jake Kring
CTO, Skylight Frames

After shopping the market, it was clear that ButterCMS was the perfect choice. It allows our developers to build powerful components and makes it easy for our marketing team to drive a better customer experience.
Hampton Catlin
Creator of Sass and Haml

We've had a great experience using ButterCMS. It gives our marketing team control over all their content and lets our engineers stay focused on improving their product. It's truly the best of both worlds.
Peter Sankauskas
CTO & AWS Community Hero

PickFu recently redesigned its whole website with ButterCMS at the center. I was able to draft new pages, circulate them to the team, edit them, and then ultimately publish in a more intuitive way than without a CMS.
Kim Kohatsu
Chief Marketing Officer, PickFu

The biggest value of Butter is that it provides our clients a seamless experience. It's a point and click, admin-friendly content management solution for any application that we've built for a client on Heroku.
Justin Ludlow
CTO of Radial Spark
- Slide #1
- Slide #2
- Slide #3
- Slide #4
- Slide #5
Composable Content

At any scale
-
Multi-channel & multi-site
Enterprises and Agencies portfolio management. Brands and client sites all in one place.
-
Marketing site
Marketing website for your SaaS, Ecommerce, Marketplace. Built in any tech stack.
-
Blog engine
Say goodbye to WordPress. Branded /blog and built-in SEO. Plugs into your existing website.
Devs love Butter



- Save time. Empower marketers to build pages and content
- Zero maintenance. We handle all maintenance, scaling & security
- Top Rated. Easiest setup and best support by G2 reviews
- Any tech stack. Global Content API with SDKs and starters for your favorite stack
No credit card needed
Executives love Butter
- Marketing + developer alignment. Experience increased productivity for your whole team
- Real ROI. Better productivity at very competitive prices
- Top Rated. Best Estimated ROI and and highest user adoption by G2 reviews
- Content at Scale. Manage multiple sites & apps in one CMS


Marketers love Butter


- Move faster. Launch content faster
- Get unblocked. Build and edit pages without dev resources
- Top Rated. 9.3 ease of use and 9.7 good partner to do business with on G2
- Easy to use. Enterprise level content workflows with WYSIWYG instant previews
No credit card needed
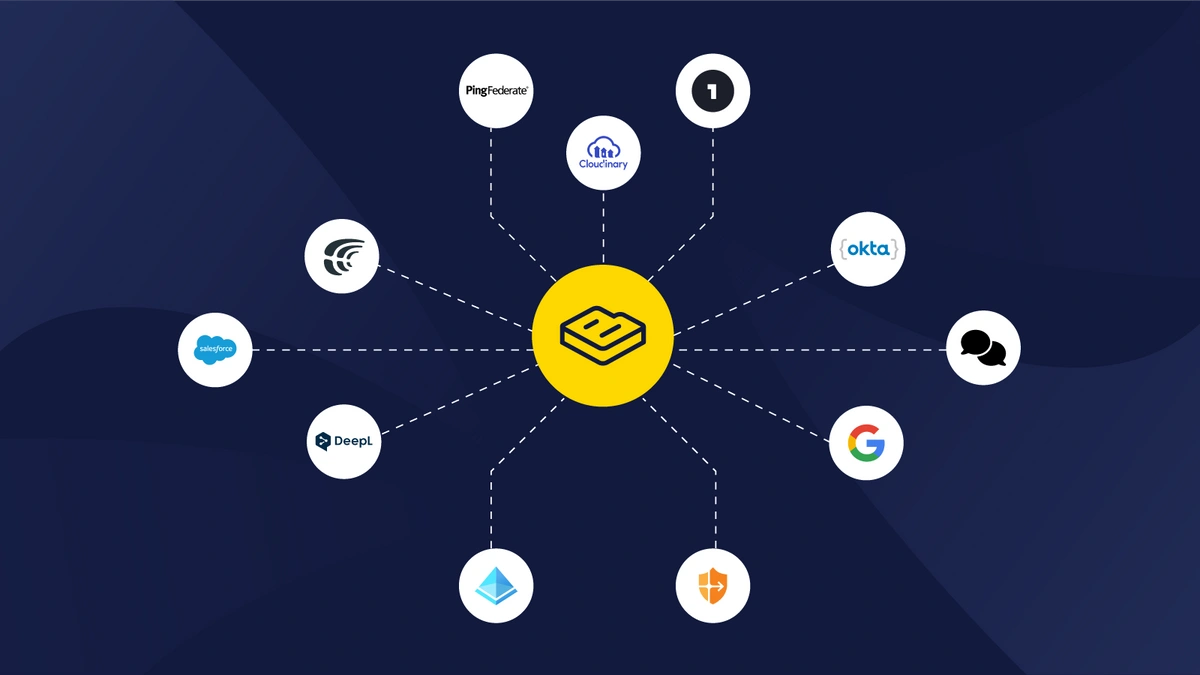
Your Composable DXP.
Support at every step.
-
Professional Support. Here to help answer your questions and get you launched quickly.
-
Secure. We're SaaS. Say goodbye to stressing over security patches
-
Scalable. Global CDNs provide maximum performance and availability






The highest-rated headless CMS on G2.
Find out why we take top marks across the board, every quarter.