


My name is Marco Palladino, co-founder and CTO of Kong, an open-source API Gateway that can be used for internal and external API traffic. In this chapter I am going to write about monolithic applications, microservices architectures, and about the monolithic-to-microservices transition that most organizations, including very large ones, are currently approaching.
We are living in a revolutionary age for software, with massive changes in the way we build, deploy and consume our services. Changes that, as we will learn, are not just technical but organizational as well. New paradigms, patterns and foundations are substantially shaping the industry and we are entering a new era, both technologically and culturally speaking. Open-source software has always been an important contributor to the industry, but in this day and age it’s becoming a major player - like never before - of enterprise adoption to new paradigms and architectures.
Back to the original topic of this chapter - somebody said that decoupling a monolithic application is like going from a whole chicken to chicken nuggets: we are moving away from large codebases to smaller and isolated services all communicating with each other. And since we have existing traffic and clients currently using our applications, I’d like to add that we need to find a way to keep the chicken alive during the refactoring.
In this chapter, I am going to explore the transition to microservices, with its pros and cons, and deep dive into the technical aspects and common mistakes that I have learned by working daily with developers and enterprise organizations. I will prioritize high priority items that everybody should know before even thinking to transition to microservices, but the topic is ultimately a very large one and I encourage the reader to learn from multiple sources.
First hand lessons on decoupling the monolith
When in late 2013 I decided to break up our monolithic application into separate services there was little narrative or examples on how to do it. At the time nobody knew about Docker yet - since it had only been around for a few months - and Kubernetes hadn’t been released yet, and pretty much most of the tooling available at the time wasn’t really a good fit for the sort of decoupling we were about to approach. Indeed, only a few progressive companies back then have been successful with their monolithic decoupling, and pretty much all of them built their own tooling from scratch to enable the transition, companies like Amazon and Netflix.
At the time Kong, which is today a popular open-source API gateway, didn’t exist yet and the company was called by another name: Mashape. Mashape was from 2012 to 2017 the largest API marketplace in the world. If you were an API developer you could search for APIs to consume and if you were an API provider you could publish your services in the marketplace. Mashape was providing the infrastructure to power the marketplace and, in order to authenticate clients and handle billing information, we were processing every single API request to our internal API gateway which, at the time, was enabling about 300,000 developers to consume about 40,000 private and public APIs.
The main platform used to be substantially a monolithic Java codebase hosted on Tomcat and communicating with a single database for pretty much every operation. There was another component, a high performing API Gateway responsible for processing every API request which was built in NGINX + Lua. The gateway technology later in mid-2015 became Kong.
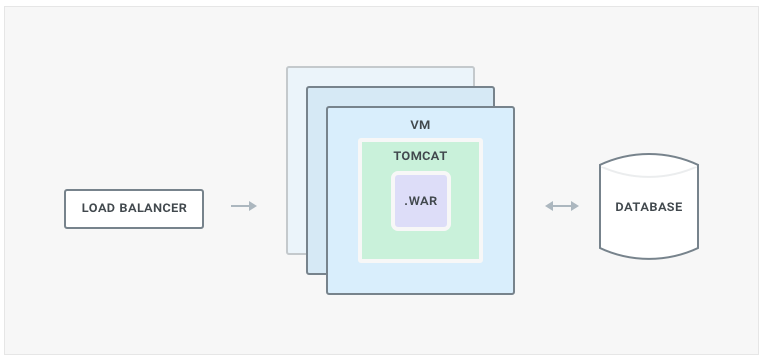
Moving forward I will focus on the monolithic webapp powering the website, excluding the API gateway. Our website was in large parts served via our backend server-side processing, with a few bits left and right written in client-side Javascript consuming ad-hoc APIs to improve the usability on specific pages (like the analytics page) using patterns popular in the early 2010, the time when large JS frameworks like Angular where just about to be released for the first time. We later extended our APIs more and more so that most of the operations could be scripted and automated, but the frontend was largely a mix of client-side API consumption and server-side processing. As every other monolithic application, the backend itself was relying primarily on function calls within the same codebase with almost no outside network call for most of its business logic - excluding database communication.
At the time we were a small team iterating and deploying multiple times per day, and having fewer moving parts allowed us to be extremely agile in the early days. But as the codebase and the team were growing more and more, this approach lead to a few problems.
First and foremost deployments became harder. Every small change required a full redeployment of the entire system and lots of team coordination, increasing our overhead and risks. As our codebase was rapidly growing and evolving (we were a startup evolving at a fast pace, after all) what used to be nice and clean boundaries between all the different components of the marketplace (like billing, analytics, catalog management) became more and more entangled over time, making those boundaries more and more blurred. In short, our marketplace fell into the same old problems and tech debt that every monolith experiences when it becomes too large.
When the codebase became increasingly hard to deploy, it made it harder to isolate failures, harder to onboard new contributors, and we knew something was fundamentally wrong. Slowly but surely these problems also affected the team performance and morale leading to an overall feeling of frustration. Then we finally made the call: we had to move away from the monolith and carve our huge codebase into smaller components. In 2013 there was little prior art on microservice oriented architectures, and as much as I want this story to be glorious, you - the reader - will soon realize that instead I will highlight a series of mistakes which in turn made our system a lot worse and not better. As I talk with teams, leaders and enterprise organizations I am still seeing the same errors happening over and over again even today with the abundance of tooling available, so hopefully this can serve as a warning to some common pitfalls.
Microservices are harder, not easier
When we first decided to transition to microservices Mashape was far from becoming Kong. At the time we were a typical early stage startup with a small team -- too small, as we later found out, to pursue the transition. Although we recognized that the old codebase was effectively slowing us down and something had to be done, transitioning to microservices in an era where microservices were not very well understood, with a small team, rushing through the pushy deadlines (that a small startup needs to constantly meet in order to iterate quickly and make early users happy) was not the most thoughtful decision. In short, we didn’t know what we didn’t know.
Before starting the transition our plan was simple, or so we thought: we would identify the biggest pain points and boundaries in our monolithic codebase and decouple them in separate services. These services wouldn’t necessarily be too small, or too large, but they would be of the right size required to handle their specific business logic within the boundary they were allocated to, and looking back this was one of the right calls we made early in the process. When it comes to microservices most developers and architects focus too much on the final size, but the reality is that those services will be as big as they need to handle their specific business logic. Too much decoupling, and we end up with too many moving parts. There is always going to be time in the future to decouple them even further as we learn the pain points of building and operating our new architecture.
As we started to approach our transition it became evident that we couldn’t just allocate all of our resources to the project, and since our existing business was still running and growing on the monolith we had to split the team in two even smaller teams: one that would maintain the old codebase, while the other one would work on the new codebase. We underestimated resource allocation, and as a side effect this also created some morale friction across the two teams, since maintaining a large monolithic application is not as exciting as working on new technologies. This problem can be more easily dealt with in a larger team. In hindsight, we should have at least considered some sort of team members rotation, and the reason it wasn’t done was because we thought it would have slowed us down. And this brings us to the next problem: time.
It probably wasn’t the right time for Mashape to undertake such a large project. The reason why we decided to reconsider our architecture in the first place was to speed up feature development moving forward. And perhaps with a perfect final microservice oriented architecture we would have been faster, but we didn’t realize how painful it would be to break down the monolith and certain areas of the codebase that have been untouched for a long time. As a result of this, we ended up being slower. Transitioning to microservices requires time, and a lot of it - it can be done in chunks, it can be done with more resources, but there are always going to be bumps along the road that are hard to predict and - as usual in our industry - the excitement of building a better system, and the engineer’s ego, can sometime result in the second-system syndrome and overpower certain concerns. The truth is that transitioning to microservices won’t happen overnight, no matter how hard we think about it and how much we plan for the transition, it’s just not going to happen quickly. And since the transition can sometimes be longer than the times it takes for a competitive market to move forward, the huge risk is leaving the business behind and damaging the company. Timing the transition is therefore as important as the transition itself.
Two ways for microservice communication
Besides the circumstances described above, one of the biggest lessons learned was understanding when to use service-to-service communication patterns as opposed to what I call asynchronous patterns. And even nowadays - in 2018 - the narrative seems to be exclusively pushing for service-to-service communication, although that’s not necessarily the best way to implement very specific use-cases. We learned this the hard way with Mashape when we had to address with critical failure scenarios that could create data inconsistencies across multiple services.
The main difference between the two patterns is that an asynchronous system won’t directly communicate with another microservice, but it will instead propagate an event that - asynchronously - another service can intercept and react to it. Usually log collectors like Apache Kafka can be used, but also RabbitMQ or cloud alternatives like - for example - AWS SQS.
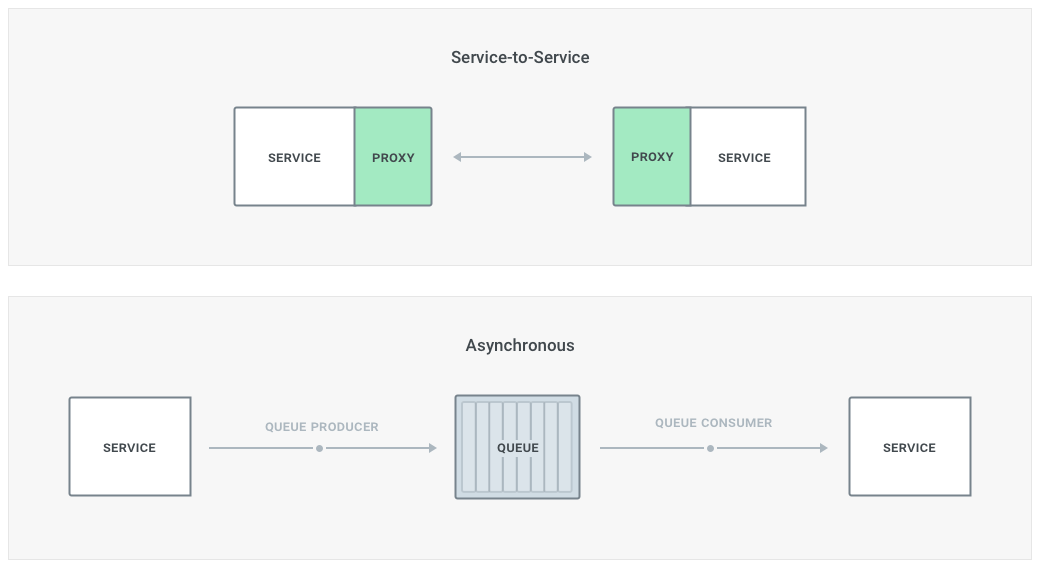
This pattern is very useful every time an immediate response is not required, since it basically implements eventual consistency within the architectural pattern since day one and you don’t have to worry about it. Therefore it makes a great candidate to propagate those eventually consistent data state changes across every microservice avoiding to create inconsistencies if something goes terribly wrong (for example when one of those services is critically down).
Let’s assume for example that we have two microservices, “Orders” and “Invoices,” and that every time an order is created an invoice also needs to be created. In a service-to-service pattern the “Orders” service will have to issue a request to “Invoices” every time an order is being provisioned, but if the “Invoices” microservice is completely down and not available eventually that request will timeout and fail. This would be true even if the request was issued by an intermediate proxy (i.e., a sidecar mesh proxy) as it will still try to make the request over and over again but eventually - if “Invoices” is still down - it will still timeout and fail, leading to data inconsistency in our system.
With an asynchronous pattern, the “Orders” microservice will create an event into a log collector/queue that will be asynchronously processed by the “Invoice” microservice whenever it decides to poll or listen for new events. Therefore even if “Invoices” is currently down for a long period of time, those invoices won’t be lost and the data will be eventually consistent across our system as soon as the microservice goes online again (and assuming that the log collector will persist the events).
Using a system like Apache Kafka also makes it easy for the developer to replay a series of events starting from a specific timestamp, in order to reproduce the state of data at any given time either locally or on staging.

There are always going to times when although a microservice is built with an asynchronous pattern in mind it will have to be consumed directly, so I wouldn’t be too surprised if the final state of the service implements both a queue listener and a regular API invocation interface.
At Mashape we eventually learned all the hard lessons, and managed to have a functioning microservice-oriented architecture down the road, but it definitely wasn’t a painless process. Today the industry provides way more tooling and platforms that help the transition than it did in 2013, and it would probably make it easier, although these tools still have rough edges and they are maturing as we speak. I wouldn’t recommend starting with a large transition without having first implemented a smaller microservice architecture, perhaps for a new feature or a new small product. Transitioning a large legacy codebase is like opening a can of worms and that prior experience will help making the right calls when the timing is right.
This is part of Microservices for Startups eBook. If you've enjoyed, please share!
All Chapters
- How teams get microservices wrong from the start
- Should you always start with a monolith?
- Microservice Boundaries: 5 characteristics to guide your design
- Five microservice testing strategies for startups
- Should you break up your monolithic application?
- Breaking Up a Monolith: Case Study
- Designing a Successful Microservices Engineering Culture
- Should you build or buy microservices?