


Microservices and monolithic architectures both have their pros and cons, and choosing which architecture to build needs to be a thoughtful decision. Microservice architectures have recently been in the spotlight and most large organizations I have been personally working with are either considering - or in the process - of transitioning to microservices, a trend that’s happening horizontally across every industry. Despite what everybody else is doing and the noise everybody is making around microservices, we need to zoom out and look at our long term goals and objectively understand if it makes sense to break up the monolith or not.
A microservice-oriented application does not make it easy to quickly build something and validate it in the market. In fact it would be quite the opposite; the amount of concerns and moving parts that microservices bring to the fight will certainly slow you down initially. If the plan is to create a prototype or validate the market for a new product, monolithic applications are still a very good choice (as long as we consider that in the long term we may have to revisit our architecture).
On the other side if we do already have an application running and we are firefighting with common issues related to an increase in size of the codebase (or the team), and if deployments are becoming increasingly painful, then microservices can fix those problems. Microservices effectively replace function calls within the monolith with network calls across different services, increasing the networking requirements and complexity of the application. Some of the new topics you will have to start thinking of are - for instance - the performance of the network, the security and reliability of all of those network calls your architecture will start making and the visibility and monitoring across the entire system. If your team currently doesn’t have a good knowledge of APIs, networking and perhaps containers (Docker, Kubernetes), then you will have to prepare the transition by making a few strategic hires that can bring this knowledge in house.
Containers and orchestration tools are not - from a technical standpoint - a requirement for microservice-oriented applications, but they can certainly help in decoupling and scaling each one of the different services you will be creating and deploying. Orchestration platforms like Kubernetes also provide some useful glue functionality out of the box to make a sense of your architecture, providing tooling that otherwise you will have to deploy - and sometimes build - by yourself (for example service discovery, network management, versioning, etc).
While a few years ago being locked-in with a cloud provider was generally accepted, I am seeing more and more enterprises reversing this trend and making technical decisions that would allow them to move their infrastructure to different cloud providers if such necessity should arise. These enterprises are thinking strategically about their architecture: when you are planning your architecture and execution on your vision down the road, with all the tooling available today there is really no excuse to be locked in with a specific vendor. Tooling like containers and Kubernetes allow your application to be replicated and deployed across different cloud providers, on-premise, or locally for development.
If you are transitioning an existing monolithic codebase to microservice without an appropriate test suite in place already, then the answer is no. You should already have - or you should start building - a comprehensive suite of both unit and integration tests before approaching any refactoring.
As we will learn in this chapter it doesn’t have to be an either/or choice: you can still keep some of your codebase as it is, and only transition the most painful and demanding business logic to a microservice- oriented architecture. Obviously you will have to glue them together in order to share state and functionality.
Finally, the decision of fundamentally transitioning from one architecture to another is strategic and not tactical, therefore it needs to be well understood by both the teams and the management. Going to microservices is not just a technology transition, but an organizational transition in the way the teams are created and managed, and in the way those teams are working and collaborating with each other. It’s not just a matter of adopting new frameworks or new tools, it’s a revolution that fundamentally changes every aspect of the software lifecycle. The transition is also not going to happen overnight and the teams need the full blessing of the leadership and their understanding of what the future, and the transition itself, will look like. Patience is a key factor while undertaking such a massive project.
A technical look into the transition
Now that we understand what monolithic and microservices bring to the table, it’s time to think about approaching the technical transition. There are different strategies we can adopt, but all of them share the same preparation tasks: identifying boundaries and improve testing.
These preparation tasks are fundamentally important to our success as we deep dive into the transition and cannot be overlooked.
Boundaries
The first thing to figure out before starting the transition is what services are we going to create and how our architecture will look like in a completed microservice architecture, how big or how small do we want them to be, and how they will be communicating with each other.
When we think of an application we usually think of a few specific macro-categories of features that have to play nicely together. For example categories like account management, billing management, checkout workflow, search features, and so on. In the early stages of our monolithic applications we are usually able to compartmentalize our code in a good enough way to get the first version of our product out of the door.
As we already know, when building a monolithic application we usually end up with all sorts of functionality in one codebase, most likely talking with the same database. When a rapidly growing product happens to have a highly coupled architecture something not-so-good starts happening as soon as the product and the team grows. Pressure to build new features, deploy them, and iterate over user’s feedback sooner rather than later will transform the codebase negatively and those clean functional boundaries between different features of the product - and the data-model - will start melting together. You will notice this behavior happening when the codebase starts feeling “messy”: helper functions all over the places, code that’s hard to test, database access done conveniently and improperly. The code becomes extremely entangled and those clean boundaries become more and more blurred.
Keeping clean boundaries is certainly a target of quality that every team should be thriving for, and depending on the maturity of the individual contributors, the review process in place, and the overall engineering culture, it’s an achievable goal. But it’s also an investment the organization needs to consciously make as an effort to create less technical debt over time, and unfortunately it’s an investment that most organizations don’t understand or are not willing to make.
Before starting the transition we need to understand the boundaries that make up our system so that we can, in a second step, extract them into services. We start with those boundaries that are more negatively impacted by the monolith, for example those that we deploy, change or scale more often than the others.
Testing
Transitioning to microservices is effectively a refactoring, therefore all the regular precautions we usually undertake before a “regular” refactoring also apply here, in particular testing.
As we go deeper into the transition we are changing how our system fundamentally works - but we want to be equally sure that afterwards all the functionalities that were once existing in the monolith are still working in our re-designed architecture. In order to do this it’s important that before attempting any change we put in place a solid and reliable suite of integration and regression tests for the monolith.
We do expect some of these tests to fail along the way, and having well tested functionality will help us track down what is not working as expected. I cannot stress enough how important this step is before we attempt to do any change.
Strategies
There are several strategies that we can approach. The first one I like to call the “Ice cream scoop strategy,” which allows us to gradually transition our monolithic application to a microservice oriented architecture by scooping out different components within the monolith into separate services. This transition is gradual and there will be times were both the monolith and the microservices exist simultaneously. In this chapter I will focus on this strategy, but first let’s explore the other two options.
Pros: gradually migrating over to microservices with reduced risks without affecting much the uptime and the end user experience.
Cons: it’s a gradual process that will take time to fully execute.
The second strategy is for companies that believe their monolith is too big to refactor and prefer to keep it as it is. Instead they choose to only build new features as microservices. Effectively this won’t fix the problems with the current codebase but it will fix problems for future expansions of the product. I call this strategy the “Lego Strategy,” as we are effectively stacking the monolithic and microservices on top of each other in a hybrid architecture.
Pros: not having to do much work on the monolith, it’s a faster transition.
Cons: the monolith will carry along all of its problems and new APIs will most likely have to be created to support the microservice-oriented features. Could be a strategy to implement to buy some time on the big refactor but ultimately we are adding more tech debt on the monolith.
The third strategy is the “Nuclear Option,” rarely adopted. The entire monolithic application is rewritten into microservices all at once, perhaps still supporting the old monolith with hot fixes and patches but building every new feature in the new codebase. Surprisingly I have met a few enterprises who decided to go with this strategy, because they assumed that working on the old monolith was not doable and decided to give up working on it.
Pros: allows to re-think how things are done, effectively we are rewriting the app from scratch.
Cons: we are rewriting the app from scratch, we may end up with a second system syndrome and the end user will be affected with a stalled monolith until the new architecture is being deployed.
Ice cream scoop strategy
This strategy assumes that the monolith will be gradually decoupled over time to reduce risks and maximize uptime - we will be scooping out features and services from the monolith into separate microservices that will be communicating with each other in order to provide the same features. These strategy has the advantage of delivering technical and business value along the way, validating the transition as we go deeper and deeper.

Assuming we have an e-commerce application with a frontend and a monolithic backend, and assuming we have a good test suite in place, we can identify a few boundaries we could extract: users management, item inventory management, orders and invoicing.

One of the first components we want to separate is the frontend from everything else. The frontend for our application is one of the components that’s going to be updated more often - for example with new content or new UI - and we want to start decoupling its lifecycle from the rest of our application. By doing so we are introducing a fundamental component that will shape the next-gen architecture we are building, APIs. In fact, APIs are the backbone of a microservice oriented architecture. We can decide to run the frontend client-side (better choice, more scalable) or still run it server-side (poor choice, less scalable) - regardless of our choice separating the frontend from the backend will introduce the first critical API in our system.
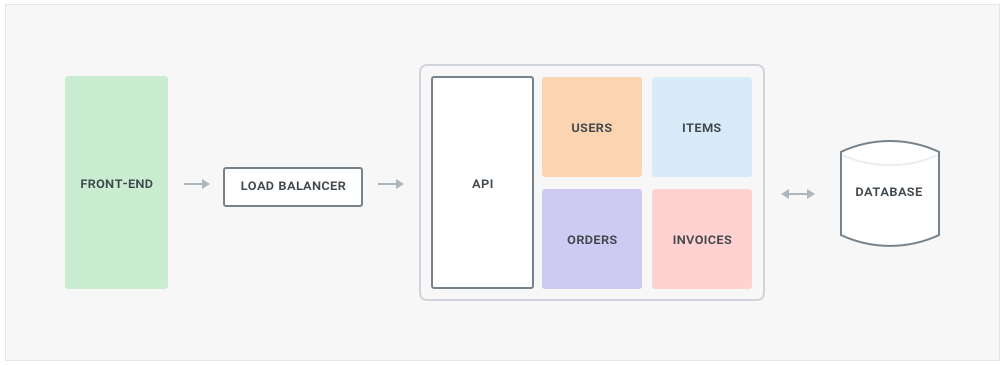
The API is still part of the monolith, but not for much longer. Having an API between the frontend and the backend logic allows us to start decoupling the monolith without disrupting the end users' activity. The API can be built on top of HTTP, RPC, or any other technology, although I would recommend HTTP/1.1 or HTTP/2 (faster) based APIs in order to leverage as much HTTP tooling as we can (for example, HTTP load balancers, caches, etc).
APIs are hard to build, and I will leave it to the reader to research best practices and examples on the topic. In short, breaking changes in an API are extremely painful and an API should be designed since day one to allow for expansibility and versioning.
Moving forward, we can now start extracting other services. For example we could decide that the “Items” management operations (ie, searching or viewing an item, etc) are very intense, and therefore it’s our next candidate.
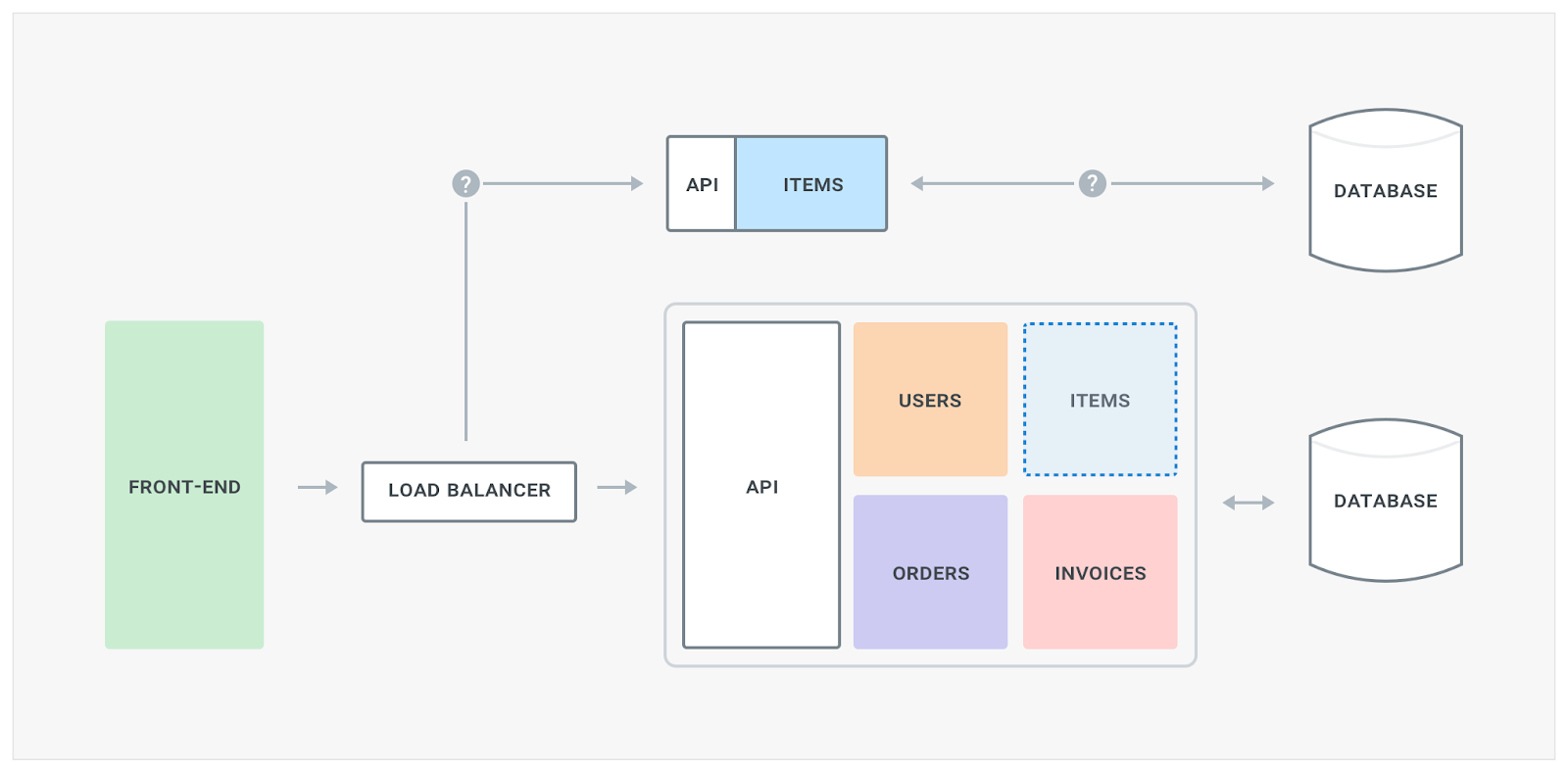
Database
The end goal for the new microservice-oriented architecture is not to rely on one database that every service utilizes. Instead, since we are decoupling the business logic in different services, we also want to decouple database access and have one database for each microservice. Sometimes this is inevitable depending on the use-case the microservice is trying to address: for example, a microservice that handles users and their data will benefit from a relational datastore while a microservice that deals with orders or logs could benefit from high-performance writes of an eventually consistent datastore like Cassandra.
Sometimes some services will indeed use the same underlying database technology, and although it would still be better to have separate database clusters dedicated to each microservice, for low throughput use cases sometimes it’s just too convenient to leverage the same datastore nodes but with data stored in different logical databases/keyspaces. For example, you might have two services that both use PostgreSQL, and as long as those microservices are using separate underlying Postgres databases, you could still have one large PSQL cluster that both microservices are talking to. I consider this to be “manageable technical debt” and a good start, but I would still have a strategy in place to start a new dedicated database cluster if one of those microservices becomes too demanding on the db. The cons of this solution is that if a microservice - for whatever reason - impacts the database uptime then the other microservices will also be impacted (since they are talking to the same db nodes), and this is to absolutely avoid down the road since it breaks compartmentalization.
Regardless of your setup we will soon encounter a big problem: consistency of our data. There is going to be a limbo period when the old codebase is still writing and reading to the underlying database, and new database for our microservices will use a separate store for our data. Therefore writes, or reads, made by the monolith won’t be visible to the microservice and vice-versa. This is not an easy problem to solve and there are a few options, including:
- Writes from the monolith are also propagated to the microservice database, and vice versa. You will need to update the monolith to write to the new system.
- We build an easy-to-use API for the old database that the microservice will use to query data from the old database. You will need to build this API in the monolith and have a temporary synchronization mechanism built into the new microservice.
- We introduce an event collector layer (ie, Kafka) that will take care of propagating writes to both datastores. You will have to build this support in both the monolith and microservice.
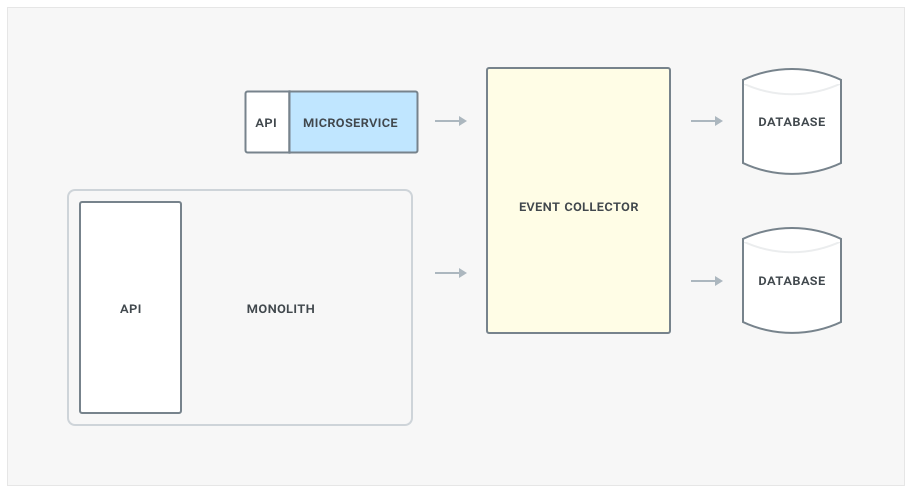
Routing & Versioning
Every microservice will be accessible by some API of some sort and each microservice will be consuming other services via their API, being totally agnostic of their underlying implementation. APIs are the entrypoint for all of our service-to-service communication. We can therefore make updates to our implementation - including fixing bugs or improving performance - and as long as we don’t change the API interface (how requests are being made and their parameters, and the response payload) other microservices will be able to still work like nothing ever happened.
Every time we make a change we don’t want to just route all the traffic to the new version of our service, after all that would be a risky move and if there are any bugs we would impact our application uptime. Instead we want to gradually move traffic over, monitor how the new version behaves, and only when we are confident enough transition the rest of our traffic. This strategy is also called a canary release, and it allows to reduce downtime caused by faulty updates.
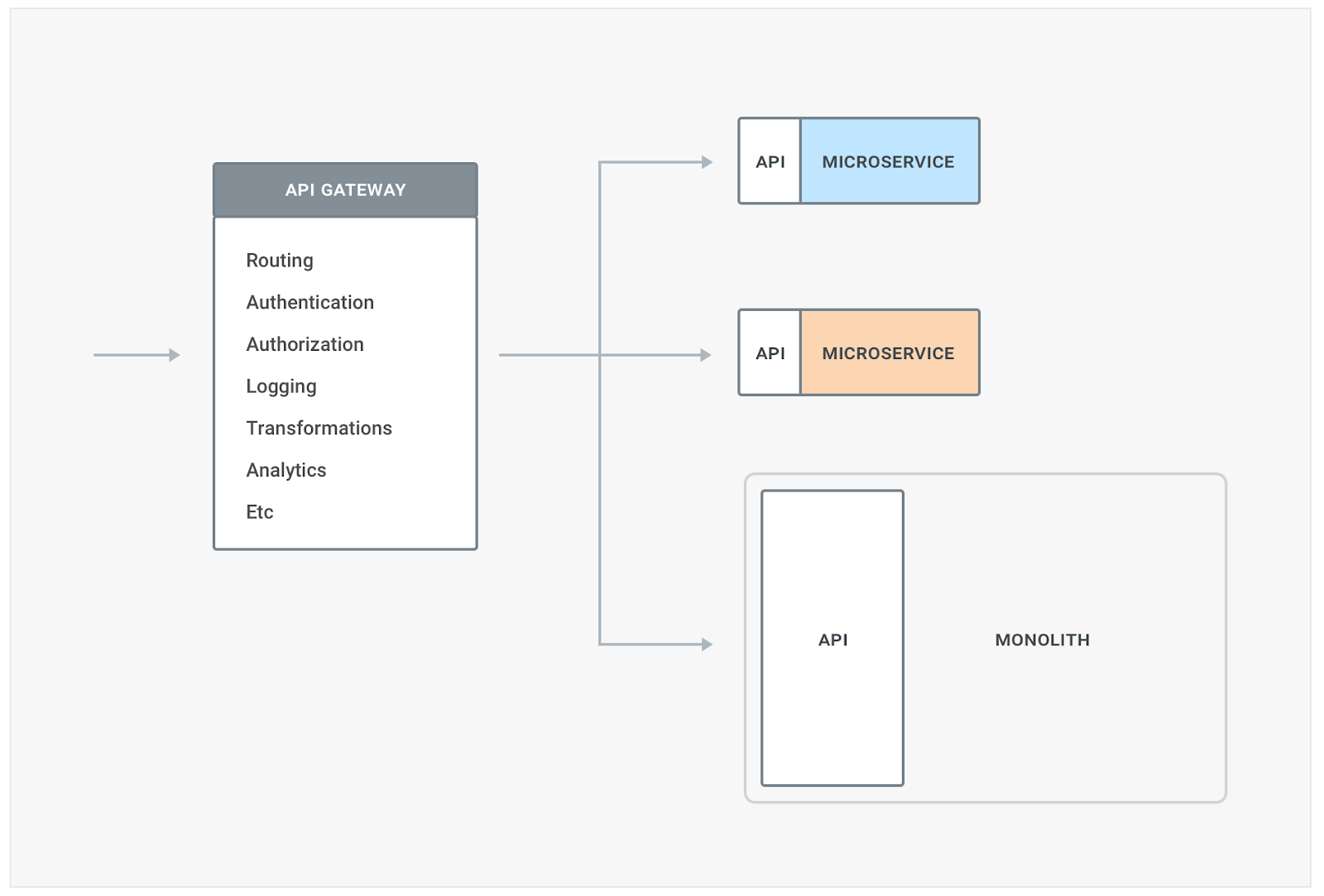
This also means we need to have a good strategy in place to route traffic among different versions of our service and monitoring tools in place to determine if any errors have been triggered. This can be done by using proxies, or gateways for north-south traffic, in the following way:
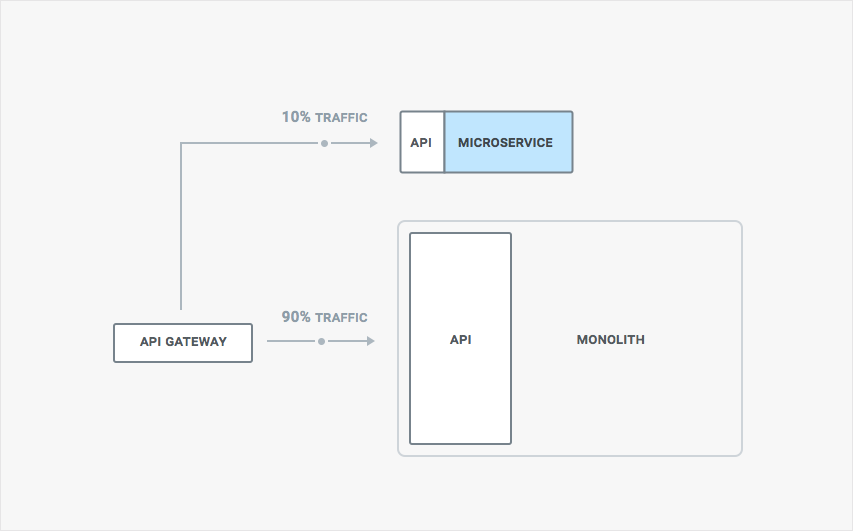
These routing capabilities will be required both when decoupling our monolith and later once you decide to upgrade our microservices to a different version. As you decouple more and more services, you soon realize that they don’t live in a vacuum but you need to provide a set of complementary features like authentication, authorization, logging, perhaps transformations, and this is where API Gateways / Ingress - like Kong - can help in trying to reduce this fragmentation - as well as providing the routing capabilities mentioned above:
Libraries & Security
Our approach needs to be realistic avoiding to apply too many changes all at the same time. Depending on our codebase we may find it useful to decouple our monolith business logic in third-party libraries that can be then used by both the monolith and the microservice. That also gives us the benefit of reflecting any bug fix or performance enhancement on both codebases while we are in our monolith/microservice limbo.
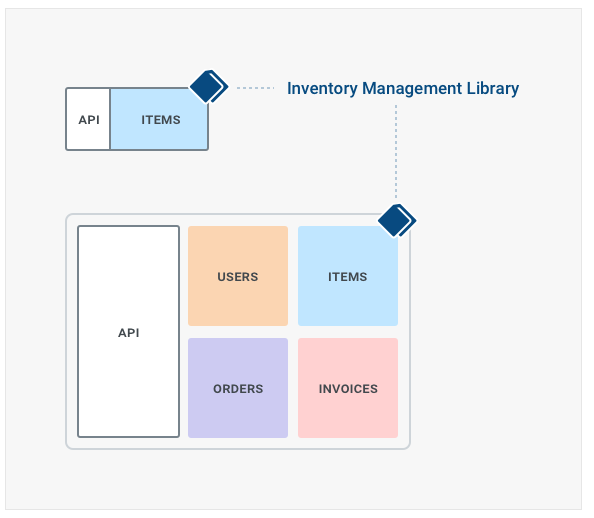
In general libraries that deal with specific logic which eventually will be implemented by only one microservice do not cause any problems, since any change in the library will require upgrading only one service, but any update to a library used by more microservices simultaneously will cause problems, since any update will have to trigger multiple re-deployments across multiple services - which we would rather avoid since it brings back old memories of the monolith. With that said, there are so many different use-cases on the topic that a one-fit-all answer would be hard to give, but generally speaking whatever roadblock prevents a microservice from being deployed independently or being compartmentalized should be removed in the long run.
Authentication and Authorization were concerns handled internally by the monolith, which can also be implemented within a library, or implemented in a separate layer of our architecture like the API Gateway. Sometimes we will have to re-design how authn and authz are being handled taking into account scalability as we add more and more microservices in our organization. We want to adopt stateless authentication/authorization and perhaps leverage technologies like JWT to achieve our goals.
Security between our microservices should be enforced with mutual TLS to make sure that unauthorized clients within our architecture won’t be able to consume them. Logging should be enabled all across the board to observe and monitor how the microservices are behaving.
Now that we have so many moving parts observability becomes a key requirement to detect anomalies, latency and high error rates. Therefore we will need health-checks configured for each one of our services, and circuit breakers that can trip and prevent cascade failures across our infrastructure if we see too many errors. Since every microservice should be stateless, we can also leverage highly available deployments across multiple availability zones/racks, regions/datacenters with eventual consistency across the entire system. When thinking of microservices it’s always a good exercise to assume we are going to deploy the entire system in multiple regions, or even multiple clouds, therefore the decoupling of the monolith needs to address these concerns.
Containers & Service Mesh
Using containers - like Docker - is not technically required although leveraging orchestration tools like Kubernetes, the de-facto container orchestration platform, can make our life a lot easier if we do indeed decide to go through this path. Kubernetes provides, out of the box, many features including facilities to scale up and down our workloads, service discovery and networking capabilities to connect our microservices. In addition to this, Service Mesh is a new emerging architecture design which aims at helping creating microservice-oriented architectures by providing a pattern to perform service-to-service communication delegating features like routing, error handling and observability to a third-party proxy - usually run in a Kubernetes sidecar alongside our microservice processes.
Service Mesh is more commonly used in the context of microservices and the word implies a mesh of services that are all communicating with each other, that is our microservice architecture. The pattern assumes that each instance of our services is not being deployed standalone, but together with a proxy process that sits on the execution path of each request and response. By doing so every time a service wants to consume another service it makes a request to its local proxy, and the proxy will take it from there and figure out how to communicate with the other microservice. On the receiving end there is another proxy process that accepts the request, and then reverse proxies it to its own underlying microservice process.
The Service Mesh pattern also introduces familiar networking concepts like the control-plane, used to administer our system, and the data-plane, which is primarily used for processing our requests. Both planes communicate together so that configuration can be propagated, and metrics can be collected.
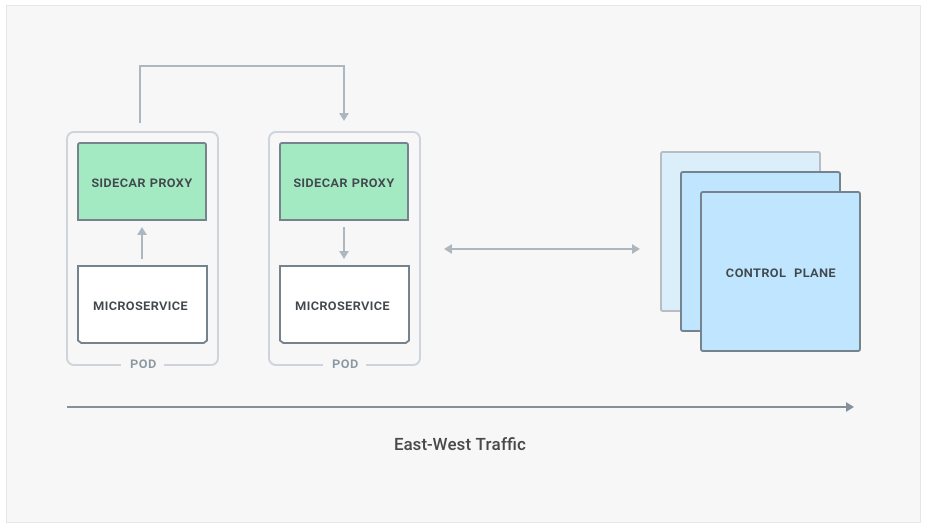
The contact points between each service are the two proxies, so that the services themselves don’t have to deal with monitoring, error handling, discovery and so on. The proxies are part of the so called data plane, and they can be configured by another architectural component - the control plane - which is responsible to collect and store user defined configuration and push it to the data plane in a transparent way. The traffic within a service mesh or, more broadly, between microservices in a data-center is called east-west traffic.
Sooner than later these services will have to be consumed by an external client that does not intimately belong to the product whose services belong to, and that communication usually requires an entrypoint - or ingress - which will the route the request to the most appropriate microservice. A client that would normally go through an ingress point could be another product in the organization, a request coming from another data-center or perhaps and external developer, mobile app or partner.
In the end state of a microservice oriented architecture you will see both service mesh and an ingress playing together to handle their respective - very different - use cases in the best way possible. Service Mesh both as a pattern and as an implementations (like Istio) are still in the early days, but are maturing at a rapid pace and 2018 will see some interesting developments.
Conclusions
Transitioning to microservices is a significant engineering investment with equal significant benefits for applications that reached a certain scale. Therefore Enterprise organizations across every industry are either approaching - or deploying - microservice architectures that can help dealing with the pains of a growing codebase and larger teams. It’s both a technical and an organizational transition as we decouple not only our code, but our teams as well.
Approaching such a radical shift cannot be achieved without a long-term plan and preparation tasks that will help us being successful with our transition, including a good testing strategy in place. It’s also a feat that’s not going to happen overnight, and will most likely include transition implementations that we build to help us along the way, that will have to be removed later on, for example when dealing with legacy database, authentication or authorization functionality.
While personally talking with enterprise architects I keep hearing that they are transitioning to microservices in order to increase internal re-use and adoption of APIs and services that other teams or departments are creating. While microservices do allow for this consumption mode, if the end goal is to foster cross-departmental collaboration then I would recommend to first consider improving internal North-South communication across those departments first, and then decoupling the monolithic apps powering those APIs as a second step.
Ultimately new patterns and technology are emerging to help promote and build microservice architectures, containers and orchestration platforms being some of them (Docker, Kubernetes), and recently Service Mesh which helps dealing with East-West traffic within the application, and although not a mature solution yet we can expect some interesting developments on its front. API Gateways will help with ingress and so called North-South traffic from both internal and external clients while transitioning away from the monolith, while service mesh can help in managing east-west traffic within the architecture of a specific product. Both service mesh and Ingress will eventually be adopted in the final state of any microservice architecture to deal with their respective use-cases, different but both required at the same time.
Asynchronous patterns should also be explored when an immediate response is not required, since they provide built-in eventual consistency and reduce the number of concerns service-to-service communication brings to the table. Most likely both patterns will be used together to deal with different use-cases, since individually none of them is a one-fits-all solution.
This is part of Microservices for Startups eBook. If you've enjoyed, please share!
All Chapters
- How teams get microservices wrong from the start
- Should you always start with a monolith?
- Microservice Boundaries: 5 characteristics to guide your design
- Five microservice testing strategies for startups
- Should you break up your monolithic application?
- Breaking Up a Monolith: Case Study
- Designing a Successful Microservices Engineering Culture
- Should you build or buy microservices?