Almost all the information on the web exists in the form of HTML pages. The information in these pages is structured as paragraphs, headings, lists, or one of the many other HTML elements. These elements are organized in the browser as a hierarchical tree structure called the DOM (Document Object Model). Each element can have multiple child elements, which can also have their own children. This structure makes it convenient to extract specific information from the page.
The process of extracting this information is called "scraping" the web, and it’s useful for a variety of applications. All search engines, for example, use web scraping to index web pages for their search results. We can also use web scraping in our own applications when we want to automate repetitive information-gathering tasks.
Cheerio is a Node.js library that helps developers interpret and analyze web pages using a jQuery-like syntax. In this post, I will explain how to use Cheerio in your tech stack to scrape the web. We will use the headless CMS API documentation for ButterCMS as an example and use Cheerio to extract all the API endpoint URLs from the web page.
Table of contents
What is web scraping?
There's all sorts of structured data lingering on the web, much of which could prove beneficial to research, analysis, and prospecting, if you can harness it. For those interested in collecting structured data for various use cases, web scraping is a genius approach that will help them do it in a speedy, automated fashion.

You may also know web scraping by another name, like "web data extraction," but the goal is always the same: It helps people and businesses collect and make use of the near-endless data that exists publicly on the web. If you've ever copied and pasted a piece of text that you found online, that's an example (albeit, a manual one) of how web scrapers function.
Unlike the monotonous process of manual data extraction, which requires a lot of copy and pasting, web scrapers use intelligent automation, allowing you to send scrapers out to retrieve endless amounts of data from across the web. It's a hands-off and extremely powerful means of collecting data for a number of applications.
How does web scraping work?
Web scraping is a simple concept, really requiring only two elements to work: A web crawler and a web scraper. Web crawlers search the internet for the information you wish to collect, leading the scraper to the right data so the scraper can extract it.

Web Crawlers
Often dubbed "spiders," web crawlers are a type of artificial intelligence (AI) that browse the web, much like you do, by searching for keywords and following links. Most web scraping projects begin with crawling a specific website to discover relevant URLs, which the crawler then passes on to the scraper.
Web Scrapers
Built to quickly extract data from a given web page, a web scraper is a highly specialized tool that ranges in complexity based on the needs of the project at hand. One important aspect of a web scraper is its data locator or data selector, which finds the data you wish to extract, typically using CSS selectors, regex, XPath, or a combination of those.
Common applications for web scraping
There are truly countless applications for web scraping, but these examples represent the most popular use cases for these tools.
Investment Strategy
Web scraping can easily uncover radical amounts of new data tailored to the needs and interests of investors. Further minimizing guesswork in investment strategies, web scraping creates value through meaningful insights that are helping to power the world's best investment firms. Examples include estimating company fundamentals, revealing public settlement integrations, monitoring the news, and extracting insights from SEC filings.
Lead Generation
Continuously generating leads is critical to all marketing and sales teams in every industry, yet generating leads organically from inbound traffic proves extremely difficult for many companies, with most finding that consistently earning organic traffic is the biggest struggle of all. At the same time, the cost of acquiring leads through paid advertising isn't cheap or sustainable, which is why web scraping is valuable. With web scraping, businesses and recruiters can compile lists of leads to target via email and other outreach methods.

Market Research
Market research plays a crucial role in every company's development, but it's only effective if it's based on highly accurate information. Web scraping unlocks access to high-quality of every shape and size data in high volume, giving way to valuable insights. This results in better market trend analysis, point-of-entry optimization, and more informed R&D practices.
News Monitoring
The power of modern media is capable of creating a looming threat or innumerable value for a company in a matter of hours, which is why monitoring news and content is a must-do. News and content monitoring are also essential for those in industries where timely news analyses are critical to success. Web scraping is applicable in all of those instances, monitoring and parsing the most relevant news in a given industry to inform investment decisions, public sentiment analysis, competitor monitoring, and political campaign planning.
Price Intelligence
Knowing how competitors are pricing items is crucial to informing pricing and marketing decisions, but collecting this ever-changing information manually is impossible. As such, price intelligence is one of the most fruitful applications for web scraping as the data it provides will enable dynamic pricing, competitor monitoring, product trend monitoring, and revenue optimization.
Real Estate
Over the past twenty years, the real estate industry has undergone complete digital transformation, but it's far from over. Many things have threatened to disrupt real estate through the years, and web scraping is yet another domino in the chain of change. With the help of web scraping, real estate firms can make more informed decisions by revealing property value appraisals, vacancy rates for rentals, rental yield estimations, and indicators of market direction.
Why use Cheerio?
There are many other web scraping libraries, and they run on most popular programming languages and platforms. What makes Cheerio unique, however, is its jQuery-based API.
jQuery is by far the most popular JavaScript library in use today. It's used in browser-based JavaScript applications to traverse and manipulate the DOM. For example, if your document has the following paragraph:
<p id="example">This is an <strong>example</strong> paragraph</p>You could use jQuery to get the text of the paragraph:
const txt = $('#example').text()
console.log(txt)
// Output: "This is an example paragraph"The above code uses a CSS #example get the element with the id of "example". text of jQuery extracts just the text inside the element (<strong> disappeared in the output).
The jQuery API is useful because it uses standard CSS selectors to search for elements, and has a readable API to extract information from them. JQuery is, however, usable only inside the browser, and thus cannot be used for web scraping. Cheerio solves this problem by providing jQuery's functionality within the Node.js so that it can be used in server-side applications as well. Now, we can use the same familiar CSS selection syntax and jQuery methods without depending on the browser.
The Cheerio API
Unlike jQuery, Cheerio doesn't have access to the browser’s Instead, we need to load the source code of the webpage we want to crawl. Cheerio allows us to load HTML code as a and returns an instance that we can use just like jQuery.
Let's look at how we can implement the previous example using Cheerio:
// Import the Cheerio library
const cheerio = require('cheerio')
// Load the HTML code as a string, which returns a Cheerio instance
const $ = cheerio.load('<p id="example">This is an <strong>example</strong> paragraph</p>')
// We can use the same API as jQuery to get the desired result
const txt = $('#example').text()
console.log(txt)
// Output: "This is an example paragraph"You can find more information on the Cheerio API in the official documentation.
Scraping the ButterCMS documentation page
The ButterCMS documentation page is filled with useful information on their APIs. For our application, we just want to extract the URLs of the API endpoints.
For example, the API to get a single page is documented below:
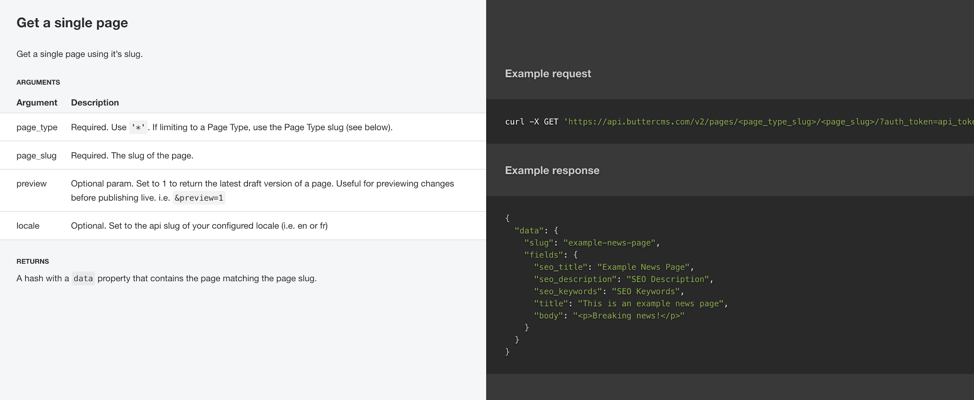
What we want is the URL:
https://api.buttercms.com/v2/pages/<page_type_slug>/<page_slug>/?auth_token=api_token_b60a008a
In order to use Cheerio to extract all the URLs documented on the page, we need to:
- Download the source code of the webpage, and load it into a Cheerio instance
- Use the Cheerio API to filter out the HTML elements containing the URLs
To get started, make sure you have Nodejs installed on your system. Create an empty folder as your project directory:
mkdir cheerio-example
Next, go inside the directory and start a new node project:
npm init
## follow the instructions, which will create a package.json file in the directory
Finally, create a index.js inside the directory, which is where the code will go.
Obtaining the website source code
We can use the Axios library to download the source code from the documentation page.
While in the project directory, install the library:
npm install axios
We can then use to download the website source code
//index.js
const axios = require('axios')
// Use the `get` method of axios with the URL of the ButterCMS documentation page as an argument
axios.get('https://buttercms.com/docs/api/').then((response) => {
// `response` is an HTTP response object, whose body is contained in it's `data` attribute
// This will print the HTML source code to the console
console.log(response.data)
})Add the above code to index.js and run it with:
<span style="font-weight: 400;"><i></i></span></code><code><span style="font-weight: 400;">node index.js</span>You should then see the HTML source code printed to your console. This can be quite large! Let’s explore the source code to find patterns we can use to extract the information we want. You can use your favorite browser to view the source code. Right-click on any page and click on the "View Page Source" option in your browser.
Extracting information from the source code
After looking at the code for the ButterCMS documentation page, it looks like all the API URLs are contained in span elements within pre elements:
<pre class="highlight shell"><code>curl -X GET <span class="s1">'https://api.buttercms.com/v2/pages/<page_type_slug>/<page_slug>/?auth_token=api_token_b60a008a'</span>\n</code></pre>We can use this pattern to extract the URLs from the source code. To get started, let's install the Cheerio library into our project:
npm install cheerio
Now, we can use the response data from earlier to create a Cheerio instance and scrape the webpage we downloaded:
// index.js
const cheerio = require('cheerio')
const axios = require('axios')
axios.get('https://buttercms.com/docs/api/').then((response) => {
// Load the web page source code into a cheerio instance
const $ = cheerio.load(response.data)
// The pre.highlight.shell CSS selector matches all `pre` elements
// that have both the `highlight` and `shell` class
const urlElems = $('pre.highlight.shell')
// We now loop through all the elements found
for (let i = 0; i < urlElems.length; i++) {
// Since the URL is within the span element, we can use the find method
// To get all span elements with the `s1` class that are contained inside the
// pre element. We select the first such element we find (since we have seen that the first span
// element contains the URL)
const urlSpan = $(urlElems[i]).find('span.s1')[0]
// We proceed, only if the element exists
if (urlSpan) {
// We wrap the span in `$` to create another cheerio instance of only the span
// and use the `text` method to get only the text (ignoring the HTML)
// of the span element
const urlText = $(urlSpan).text()
// We then print the text on to the console
console.log(urlText)
}
}
})
Run the above program with:
node index.js
And you should see the output:
'https://api.buttercms.com/v2/posts/?auth_token=e47fc1e1ee6cb9496247914f7da8be296a09d91b'
'https://api.buttercms.com/v2/pages/<page_type_slug>/<page_slug>/?auth_token=e47fc1e1ee6cb9496247914f7da8be296a09d91b'
'https://api.buttercms.com/v2/pages/<page_type>/?auth_token=e47fc1e1ee6cb9496247914f7da8be296a09d91b'
'https://api.buttercms.com/v2/content/?keys=homepage_headline,homepage_title&auth_token=e47fc1e1ee6cb9496247914f7da8be296a09d91b'
'https://api.buttercms.com/v2/posts/?page=1&page_size=10&auth_token=e47fc1e1ee6cb9496247914f7da8be296a09d91b'
'https://api.buttercms.com/v2/posts/<slug>/?auth_token=e47fc1e1ee6cb9496247914f7da8be296a09d91b'
'https://api.buttercms.com/v2/search/?query=my+favorite+post&auth_token=e47fc1e1ee6cb9496247914f7da8be296a09d91b'
'https://api.buttercms.com/v2/authors/?auth_token=e47fc1e1ee6cb9496247914f7da8be296a09d91b'
'https://api.buttercms.com/v2/authors/jennifer-smith/?auth_token=e47fc1e1ee6cb9496247914f7da8be296a09d91b'
'https://api.buttercms.com/v2/categories/?auth_token=e47fc1e1ee6cb9496247914f7da8be296a09d91b'
'https://api.buttercms.com/v2/categories/product-updates/?auth_token=e47fc1e1ee6cb9496247914f7da8be296a09d91b'
'https://api.buttercms.com/v2/tags/?auth_token=e47fc1e1ee6cb9496247914f7da8be296a09d91b'
'https://api.buttercms.com/v2/tags/product-updates/?auth_token=e47fc1e1ee6cb9496247914f7da8be296a09d91b'
'https://api.buttercms.com/v2/feeds/rss/?auth_token=e47fc1e1ee6cb9496247914f7da8be296a09d91b'
'https://api.buttercms.com/v2/feeds/atom/?auth_token=e47fc1e1ee6cb9496247914f7da8be296a09d91b'
'https://api.buttercms.com/v2/feeds/sitemap/?auth_token=e47fc1e1ee6cb9496247914f7da8be296a09d91b'
Conclusion
Cheerio makes it really easy for us to use the tried and tested jQuery API in a server-based environment. In fact, if you use the code we just wrote, barring the page download and loading, it would work perfectly in the browser as well. You can verify this by going to the ButterCMS documentation page and pasting the following jQuery code in the browser console:
const urlElems = $('pre.highlight.shell')
for (let i = 0; i < urlElems.length; i++) {
const urlSpan = $(urlElems[i]).find('span.s1')[0]
if (urlSpan) {
const urlText = $(urlSpan).text()
console.log(urlText)
}
}You’ll see the same output as the previous example:
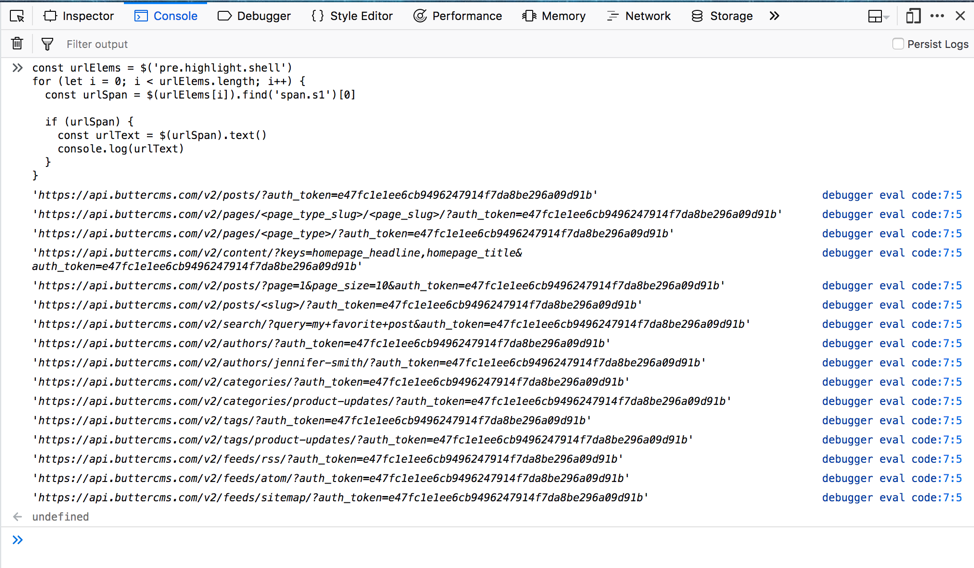
You can even use the browser to play around with the DOM before finally writing your program with Node and Cheerio.
One important aspect to remember while web scraping is to find patterns in the elements you want to extract. For example, they could all be list items under a common ul element, or they could be rows in a table element. Inspecting the source code of a webpage is the best way to find such patterns, after which using Cheerio's API should be a piece of cake!