For the past few years, we’ve encountered many IT buzzwords, some of them being clever marketing strategies and some being actual new approaches which have changed the way software is developed. When we talk about ‘serverless’, we can say with confidence that it is not a marketing trick or strategy but an architecture worth exploring. In fact, Microsoft, Amazon, and Google have all heavily invested in serverless computing, notably improving their existing applications.
In this guide, I will dive into the way serverless architecture works, explain which new patterns and abilities it offers for developers and product managers, how it can increase business value, as well as explain some of the most commonly asked questions about serverless.

What is Serverless?
General information
Contrary to its name, serverless architecture actually does have servers, but the difference is that they are not hosted by you, not managed by you, nor do you have to deal with them in any way except to invoke specific functions when needed. It is a software design pattern in which your application is split up into separate functions held in temporary containers hosted by third party of your choice and waiting to be invoked, thus taking care of dynamic memory allocation, meaning using resources only when you really need it to complete a specific task. You can think of it as a “BaaS (Backend as a service)” or “FaaS (Function as a service)”, which is what it is actually commonly referred to as.
So how do you benefit from serverless architecture?
First of all, you can completely forget about:
- Maintenance.
- Security updates.
- Provision.
- Scaling and so much more.
A third-party BaaS such as AWS (Amazon Web Services) or Microsoft Azure maintains the security of the server function, manages the updates and ensures it scales to masses.
Architecture
To get a better grasp of how serverless works, let us compare it to something we all find familiar.
Traditional

- The request starts with user interaction on the client
- The request and its data are sent to a server and processed through various middlewares, this can include authentication, IP whitelists, etc.
- The processed request is finally stored in the database
We notice that in this example authentication, IP whitelists and the processing of the request are all handled in the same block, always taking space, even when we do not need it. Let’s see how serverless differs.
Serverless
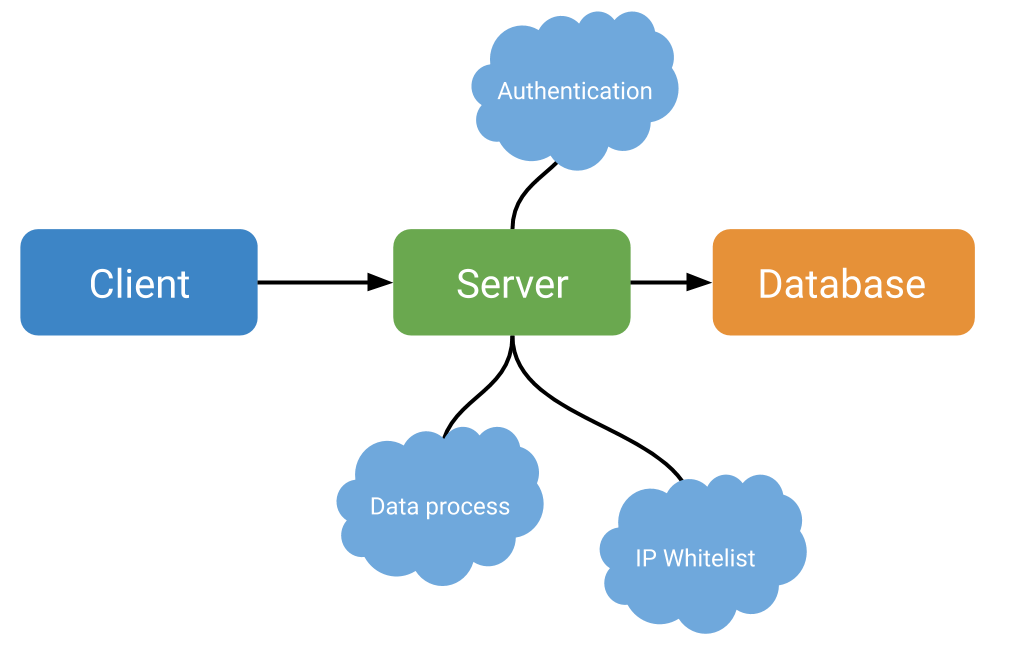
- The request starts with a user interaction on the client
- The request and its data are sent to a server
- Function for Authentication is invoked
- Function for Data process is invoked
- Function for IP Whitelist is invoked
- The processed request is finally stored in the database
Now instead of using all of our resources in one block, we have dispersed the server block into many other blocks which are only called when needed. Now, this might sound and look familiar to Microservices, and it actually is. Microservices and Serverless are commonly used together and hold many common practices when dispersing our application.
Serverless with ButterCMS
In order to further understand the semantic and workflow regarding Lambda functions and serverless architecture, we are going to mimic ButterCMS post fetching using serverless methods.
Lambda functions are often held in a directory called functions which is recognized by the serverless host of your choice, therefore, our structure in a real-world project would look something like this (simplified):
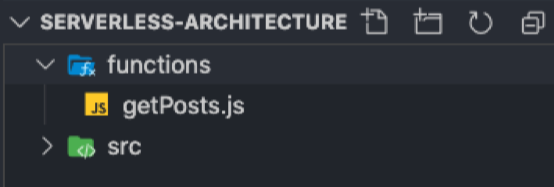
Each lambda function should consist of an event, context, and a callback, like so:
exports.handler = function(event, context, callback) {
}In our case, getPosts.js will need to handle the retrieval of ButterCMS posts and sending them to the client:
const butterCMS = require('buttercms')('your_api_token');
exports.handler = function(event, context, callback) {
butterCMS.post.list({ page: 1, page_size: 10 })
.then((response) => {
const body = JSON.stringify(response);
callback(null, {
statusCode: 200,
body,
})
})
}In this basic example, I am immediately calling callback function returning the body consisting of ButterCMS posts.
What is left depends on the hosting provider of your choice. Netlify uses .toml file to specify which command to build the lambda functions with, and where to search like this (simulation of how it should look like):
[build]
functions = "lambda"
Command = "run-lambda"In the end, our structure would look something like this:
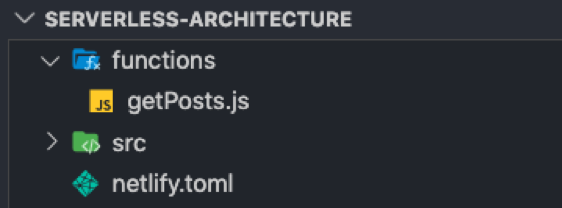
Now our server will invoke the lambda function to fetch ButterCMS posts only when needed, and use the computation resources of the provider, meaning you do not have to worry as to whether you have optimized your server environment or not, since someone else is doing it for you.

When should you (not) use serverless?
There is rarely a specific pattern or architecture which we can apply for every application and business idea, serverless is great, but sometimes going traditional might be a better option.
Let’s take a look at some of the good and bad sides of serverless.
Cons of serverless
Hard to find developers
Serverless is still an idea that is slowly adapting into day-to-day software development, and it is not yet a familiar topic to most developers, since they can get what they want with the traditional architecture. This means that you might get a set back when hiring new developers since they might feel intimidated going into unexplored areas.
Latency
When using serverless architecture your dispersed functions are not constantly active, but only when they are invoked and called, this means that there will be a slight latency for the function to “boot” and only then start working on the request. This only happens when a function has not been called a specific amount of time, but you can easily see how it can become a problem.
Difficult migration
If you are planning on migrating an enterprise-level application from traditional to serverless, it might be more difficult than you think. After all, traditional and serverless are two completely different approaches and architecture types.
Predictable workload
If your current application has a consistent and predictable workload, you might want to use traditional architecture as opposed to serverless, as it might be, taking all the factors into consideration, of course, less expensive.
Pros of serverless
Reduced cost
Most third-party providers such as AWS will offer pay-as-you-go model instead of paying a lot of money upfront. Related to that, when using serverless architecture you are always paying only for what you use, and how much you use.
Scalability
When using serverless, your provisions and demands will automatically scale with the rate of your users, meaning you do not have to worry about unexpected growth or usage in the future.
Shifting focus
Instead of focusing on managing the server, with serverless architecture, you can let your developers completely focus on increasing the business value, and let everything else be handled by third-parties.
Conclusion
Serverless architecture holds great values both for developers and product managers, as both can completely focus on the business value and not on the maintenance, security or scalability of the server functions.
Check our guide on how to use serverless in practice with Netlify and ButterCMS.